Crystal 的平行處理


Crystal 在將平行處理作為一級公民方面邁出了一大步。簡而言之,您可以在執行階段設定工作執行緒的數量,並且每個新的 Fiber 都將被安排在其中一個執行。通道和 select 將無縫運作。您可以在工作執行緒之間共享記憶體,但您可能需要注意一些同步,以保持狀態一致。
這項工作需要大量的努力,但由於重構、設計討論和嘗試進行平行處理,它肯定變得更輕鬆。無論是否合併,所有過去的工作都作為參考,以在過程中仔細檢查想法。
在本文中,我們將嘗試涵蓋所有新的功能描述、設計、我們面臨的挑戰以及後續步驟。如果您想立即開始使用它,第一部分就足夠了。最終目標是能夠使用所有可用的 CPU 能力,但又不會過度改變語言。因此,您可以在文章末尾找到一些挑戰和未完成的工作。
如何使用它,快速指南
為了利用這些功能,您需要使用 preview_mt 支援來建置您的程式。最終這將成為預設值,但目前您需要選擇加入。
正如您將在本文中讀到的,資料可以在工作執行緒之間共享,但使用者有責任避免資料競爭。一些 std-lib 部分仍需要重做,以避免不健全的行為。
- 使用
-Dpreview_mt建置程式。crystal build -Dpreview_mt main.cr - 執行
./main。(可選地,指定工作執行緒的數量,如CRYSTAL_WORKERS=4,預設值為4)
API 中第一個頂層的變更是,當產生新的 Fiber 時,您可以指定是否要讓新的 Fiber 在同一個工作執行緒中執行。
spawn same_thread: true do
# ...
end
如果您需要確保某個執行緒本地狀態或呼叫者是同一個執行緒,這特別有用。
早期基準測試
本節中顯示的基準測試是從 bcardiff/crystal-benchmarks 使用 manastech/benchy 在 c5.2xlarge EC2 執行個體中產生的。
矩陣乘法
矩陣相乘是一個可以平行化且可良好擴展的過程。它也恰好沒有 I/O,因此是分析 CPU 密集型情境的好例子。
在此範例中,當使用多執行緒編譯時,一個工作執行緒將委派並等待每個座標的結果完成,而其他工作執行緒將會挑選計算要求並處理它們。
當我們比較單執行緒與執行實際計算的 1 個工作執行緒時,我們可以觀察到使用者時間有所增加。由於多執行緒中較重的簿記和同步相較於單執行緒,因此速度較慢。但是,一旦新增工作執行緒,使用者將體驗到效能的大幅提升。預期所有執行緒在此情境中以最高速度執行。
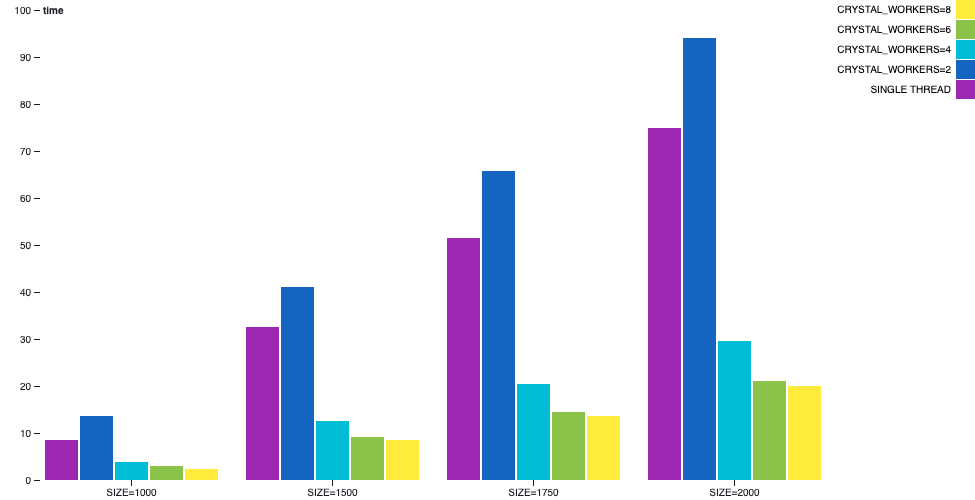
Hello World HTTP 伺服器
通常出現的合成基準測試是一個 HTTP 伺服器,它會回應 hello world 給 GET / 要求。在處理每個請求並建立簡短的回應時,通常不需要內容切換,因為在建立回應時沒有 I/O 作業。
例如,在下圖中,我們可以描繪 hello-world-http-server 範例的行為。 wrk 工具在同一部機器上執行,持續 30 秒,使用 2 個執行緒和 100 個連線。輸送量有顯著的增加。
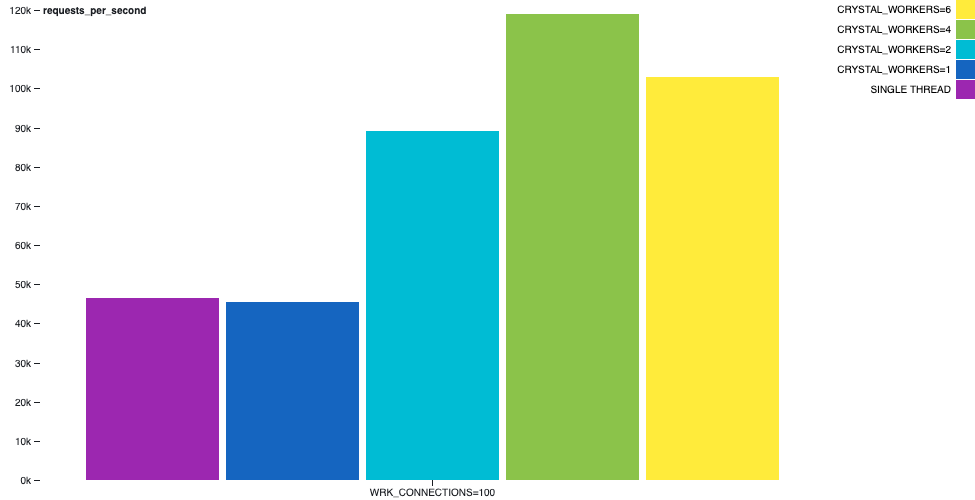
通道質數產生
在 channel-primes 範例中,質數是透過以某種順序鏈結多個通道來產生的。第 n 個質數將在列印之前經過 n 個通道。這可以被視為一種病態的情境,因為該演算法無法以顯而易見的方式平衡,而且發生了大量的通訊。
在此範例中,我們可以觀察到多執行緒並非萬能藥。單執行緒的效能仍然優於多執行緒。
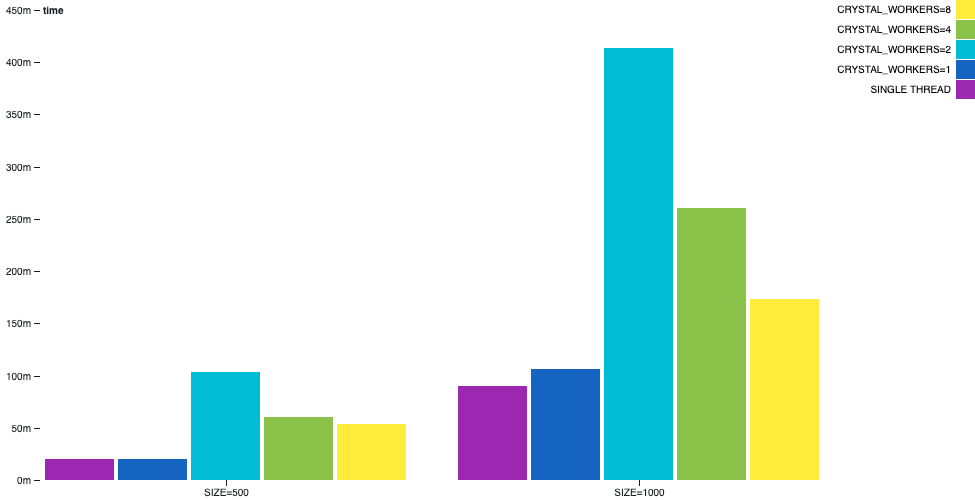
儘管,取決於工作執行緒的數量,牆上時間差異較不明顯,但 CPU 時間差異將會很大。
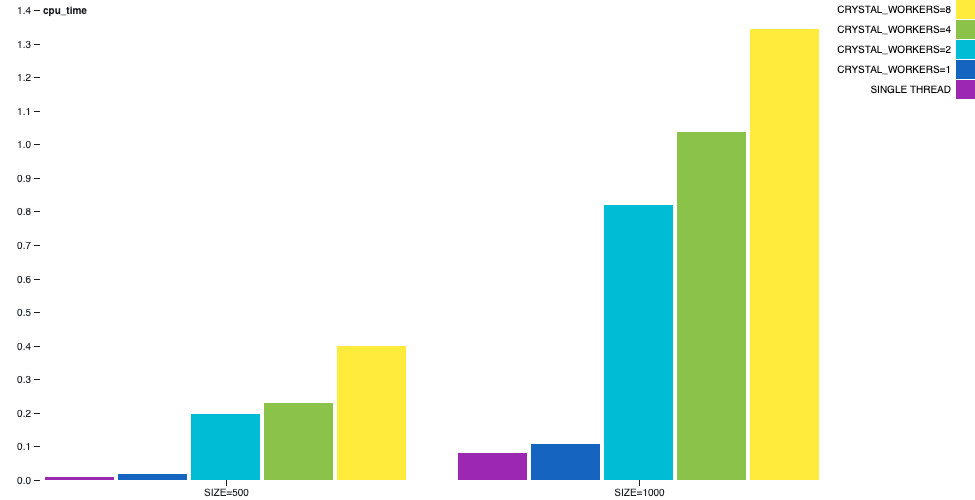
詳細描述
我們希望在不改變語言本質的情況下支援平行處理。程式設計人員應該能夠以執行中的 Fiber 為單位來思考、存取資料,並且在大多數情況下,不關心程式碼在哪個執行緒中執行。這意味著執行緒和 Fiber 之間共享資料。並盡可能將執行緒隱藏在使用者之下。
在此過程中,我們需要處理執行階段的一些核心方面的內部實作和設計的變更。我們還需要修復編譯器本身的一些問題:其中一些問題被提取並獨立提交。最後但並非最不重要的一點是,關於語言本身健全性和安全性的一些問題目前受到啟用多執行緒的影響。
在單執行緒模式下,有一個工作執行緒和一個事件迴圈。事件迴圈負責恢復正在等待 I/O 完成的 Fiber。在多執行緒模式下,每個工作執行緒都有自己的事件迴圈,它們基本上作為先前機制的多個執行個體工作,但具有一些額外功能。
每個工作執行緒之間的記憶體可以共享且是可變的。這現在和未來都將是許多頭痛的根源。您將需要透過鎖定來同步對它們的存取,或使用一些可以處理並行存取的適當資料結構。
通道能夠透過不同的工作執行緒傳送和接收訊息,而無需更改 API,並且應該用作 Fiber 之間通訊和同步的主要方法。
select 陳述式本身需要一些額外的注意。 select 在不同的通道上注入許多接收器和傳送器。一旦其中一個滿足 select,其餘的接收器和傳送器都需要被忽略。為此,當一個 Fiber 作為傳送器或接收器在 select 操作中排隊時,會建立一個 SelectContext 來追蹤整個 select 的狀態。 Channel#dequeue_receiver 和 Channel#dequeue_sender 中有邏輯可以跳過它們,如果 select 已經完成。
一旦程式開始,就會根據環境變數 CRYSTAL_WORKERS 的值初始化工作執行緒。每個工作執行緒都有自己的 Scheduler 和 runnables 佇列。
即使在多執行緒模式下,在初始化工作執行緒之前,仍然有一段短時間程式只會使用一個工作執行緒工作。這發生在初始化一些常數和類別變數時。
透過 Scheduler,有一些條件可以保護多執行緒模式下的狀態。儘管佇列是獨立的,工作者之間仍需要溝通以派送新的纖程。如果目標工作者沒有處於休眠狀態,新的纖程可以直接加入佇列(請注意,佇列是從目前的工作者存取的,因此需要同步)。如果目標工作者處於休眠狀態,則會使用管道傳送新的纖程以執行,並透過事件迴圈喚醒工作者。每個工作者執行緒在其排程器中都會建立一個管道。這是在 Scheduler#run_loop、 Scheduler#send_fiber、 Scheduler#enqueue 中處理。
現在由哪個工作者執行緒執行纖程是以循環方式決定的。此政策未來可能會根據每個工作者的負載指標進行變更。但我們選擇了我們能想到的最簡單的邏輯,如果需要,它將作為未來改進的基準。
為了讓排程盡可能簡單,一旦纖程開始在工作者執行緒中執行,它永遠不會遷移到另一個執行緒。當然,它可以被暫停和恢復。但我們明確選擇在沒有纖程竊取的情況下開始。
API 變更
編譯多執行緒程式
目前,使用多執行緒支援編譯程式的功能在 preview_mt 標誌後方提供。並請檢查您使用的是 Crystal 0.31.0(尚未發佈)或本地建置的 master 版本。
$ crystal --version
Crystal 0.31.0
$ crystal build -Dpreview_mt main.cr -o main
在執行時設定工作者執行緒的數量
工作者執行緒的數量可以透過 CRYSTAL_WORKERS 環境變數自訂。其預設值為 4。
$ ./main # will use 4 workers
$ CRYSTAL_WORKERS=4 ./main
$ CRYSTAL_WORKERS=8 ./main
spawn
預設情況下,使用 spawn 建立的新纖程可以在任何工作者執行緒中執行。如果您需要相同的纖程在目前的工作者執行緒中執行,可以使用 spawn(same_thread: true) { ... }。這對於某些使用執行緒本地儲存的 C 函式庫很有用。
互斥鎖
Mutex 仍然是請求跨纖程運作的鎖定的方式。沒有實際的 API 變更,但值得注意的是,此行為在多執行緒模式下仍然有效。你們有些人可能知道內部 Thread::Mutex 的存在,它是 pthread 的包裝器。不建議直接使用 Thread::Mutex,除非您真的知道自己在做什麼以及為什麼要這樣做。請使用頂層的 Mutex。
通道
重新審視了關閉通道的行為。從現在開始,無論是在單執行緒或多執行緒程式中,您都可以在已關閉的通道上執行接收動作,直到已傳送的訊息被消耗完畢。這是有道理的,因為否則需要同步佇列和通道狀態。當然,一旦通道關閉,就無法透過它傳送新訊息。
Channel(T) 現在代表無緩衝和緩衝通道。初始化它們時,請分別使用 Channel(T).new 或 Channel(T).new(capacity)。
Fork
混合使用 fork 和多執行緒程式會產生問題。有一些參考資料描述了該情況下的問題
fork 方法在多執行緒中不可用,並且可能會作為公開 API 消失。std-lib 仍然需要 fork 來啟動子進程,但這種情況是安全的,因為 fork 之後會執行 exec。
另一個可能需要 fork 的情況是將進程守護化,但這個故事仍然需要進一步發展。
鎖
在 Crystal::SpinLock 中有一個自旋鎖的內部實作,當在單執行緒中編譯時,其行為類似於 Null-Lock。在 Crystal::RWLock 中也有一個讀寫鎖的內部實作。
這些鎖用於運行時,不應作為公開 API 使用。但了解它們的存在是件好事。
挑戰
在達到目前的多執行緒支援設計之前,我們經歷了多次迭代。其中一些由於效能原因而被捨棄,但在本質和 API 上與目前的設計相似。其他想法啟發我們在進程之間建立某種程度的隔離。擁有明確的邊界使得減少鎖定和同步變得更簡單。其中一些設計,部分受到 Rust 的影響,會導致進程之間可共享和不可共享的類型,以及新的閉包類型來模擬它們是否可以或不可以傳送到另一個進程。還有其他草案想法,但我們最終確定了更符合當前執行纖程存取共享資料的程式性質的東西,因為我們找到了一個我們認為效能足夠好的實作。除了讓運行時保持運作的實作細節之外,還有一些關於語言語義的故事仍然需要發展,但只要您同步共享狀態,您應該是安全的。
通道的生命週期發生了一些變化。簡而言之,當纖程正在等待通道時,該纖程不再是可執行的。但是現在,等待的通道操作已經有一個指定的記憶體插槽,應該在其中接收訊息。當訊息要透過該通道傳送時,它將被儲存在指定的記憶體插槽中(共享記憶體 FTW)。最後,暫停的纖程將被重新排程為可執行,第一個操作將是讀取並傳回訊息。這可以在 Channel#receive_impl 方法中看到。如果等待的纖程在處於休眠狀態的執行緒中(沒有可執行的纖程可用),則用於傳遞新纖程的同一管道會被用來將纖程加入休眠執行緒的佇列中,喚醒它。
在實作通道和 select 的變更時,我們需要處理一些邊角情況,例如 select 在同一通道上執行傳送和接收。我們也發現自己正在重新思考通道表示的恆定性。當我們達到與 Go 的通道具有相似約束的設計時,這對我們來說意義重大。
(..) 至少 c.sendq 和 c.recvq 其中一個為空,除非在使用 select 語句的情況下,一個非緩衝通道同時有一個 goroutine 被阻塞進行傳送和接收 (...) source
上述通道機制之所以有效,是因為事件迴圈的設計方式。每個工作者執行緒在 Scheduler#run_loop 中都有自己的事件迴圈,它會從可執行佇列中彈出纖程,如果為空,則會等待直到透過該工作者執行緒的管道傳送纖程。此機制不僅適用於通道,也適用於一般 I/O。當需要等待 I/O 操作時,目前纖程將保持在 IO 內部佇列的讀取器或寫入器佇列中,直到 IO::Evented#evented_close 中完成事件。同時,工作者執行緒可以繼續執行其他纖程或進入閒置狀態。執行 I/O 的纖程由 Scheduler.enqueue 恢復,這將處理與忙碌或閒置執行緒通訊的邏輯。
對於與 libevent 的整合,我們還需要為每個工作者執行緒初始化一個 Crystal::Event::Base。我們希望 IO 可以在工作者之間直接共享,並且它們每個都需要參考一個包裝 LibEvent2::Event 的 Crystal::Event。Crystal::Event 綁定到單個 Crystal::Event::Base。解決方案是每個 IO(透過 IO::Evented)都有一個事件和等待它的纖程,它們在每個執行緒的雜湊中建立索引。當事件在執行緒上完成時,它將只能通知該執行緒的等待纖程。
@[ThreadLocal] 註釋並未廣泛使用,並且在 OpenBSD 和其他平台上存在一些已知問題。需要一個內部的 Crystal::ThreadLocalValue(T) 類別來模擬該行為,並且用於 IO 的底層實作中。
常數和類別變數在某些情況下會延遲初始化。我們希望最終能改變這種情況,但目前在初始化期間需要鎖定。將鎖放在哪裡仍然是一個挑戰。因為它不能放在常數中,對嗎?編譯器熟知的內部函數 __crystal_once_init 和 __crystal_once 都被引入並用於常數和類別變數的延遲初始化函數中。
我們提到過,起始的排程演算法是循環調度(round-robin),不涉及纖程竊取。我們曾嘗試為每個 worker 建立負載指標,但由於 worker 之間可以互相溝通來委派新的纖程,計算負載會需要更多狀態同步。此外,在目前的實作中,用於溝通的管道裡有纖程的參考,因此 @runnables 佇列的大小並不是準確的指標。
過去 GC 有多執行緒支援,但效能不夠好。我們最終實作了一個在上下文切換(讀取器)和 GC 收集(寫入器)之間的 RW-Lock。這個 RW-Lock 的實作靈感來自 Concurrency Kit,且不使用 Mutex。
不出所料,但值得注意的是,使用多執行緒支援建構的編譯器尚未能利用核心。到目前為止,編譯器在除錯模式下建構程式時使用 fork。因此,由於先前描述的問題,--threads 編譯器選項在多執行緒模式下會被忽略。這是一個 fork 的使用案例,未來將不再支援,需要使用其他結構重寫。
我們可能會目標保留單執行緒模式:多執行緒並非總是比較好。這可能會影響到 Shard 的領域。目前尚不清楚 Shard 是否會明確地被限制為只能在其中一種模式下運作,而不能在另一種模式下運作,如果是這樣,又該如何聲明它。
某些記憶體表示法和編譯器發出的低階指令在多執行緒模式下無法順利運作。至少,我們需要防止程式崩潰,以保持語言的健全性。同樣地,只要對共享資料的存取是同步的,就沒問題,但這意味著程式設計師有責任,而語言本身不夠安全。在接下來的章節中,我們將描述一些情境以及目前解決這些問題的狀態。
語言型別安全
當不同的執行緒同時存取資料結構時,如果沒有同步,指令可能會交錯執行,導致意外的結果。這個問題並不新鮮,許多語言都有這個問題。當處理像 Array 這樣的資料結構時,在最壞的情況下,可以考慮在公共 API 周圍進行一些同步。但有時,不一致的狀態會以更微妙的方式顯現。
如果語言允許值型別的大小大於可以原子寫入的記憶體量,那麼您可能會注意到一些奇怪之處。假設我們有一個共享的 Tuple(Int32, Bool),其中一個執行緒不斷設定值為 {0, false},第二個執行緒設定值為 {1, true},而第三個執行緒會讀取該值。由於指令交錯,最後一個執行緒會不時發現值為 {1, false} 和 {0, true}。這裡沒有發生任何不安全的事情,它們是 Tuple(Int32, Bool) 的可能值,但從未寫入的值可以被讀取是很奇怪的。許多具有任意大小值型別的語言通常會出現這個問題。
在 Crystal 中,值型別和參考型別之間的聯集表示為一個型別 ID 和值本身的元組。Int32 | AClass 的聯集保證不會有 nil 值。但由於交錯,可能會出現 nil 的表示,並會發生空指標例外(在本例中為程式崩潰)。
關於 Array,也會發生類似的情況。參考型別的 Array(沒有 nil 值)可能會導致程式崩潰,因為一個執行緒可能會在另一個執行緒解除參考最後一個項目時移除該項目。移除項目會在記憶體中寫入零,因此 GC 可以回收該記憶體,但零位址不是可以解除參考的值。
有幾個想法可以用不同的方式執行聯集的程式碼產生。其中一個想法已經在運作,但代價是增加了程式的記憶體佔用和二進位檔大小。我們希望迭代其他替代方案,並在選擇一個之前比較它們。目前,您需要知道在類別變數、實例變數、常數或閉包變數中可能出現的共享聯集是不安全的(但將會是安全的)。
為了處理 Array 的不安全行為,需要討論在共享可變資料結構中可能希望的不同方法和保證。最強的保證類似於序列化其存取(想想每個方法周圍都有一個 Mutex);較弱的保證是存取不會被序列化,但始終會導致一致的狀態(認為每次呼叫都會產生一致的最終狀態,但不保證會使用哪一個);最後,沒有保證是允許對狀態進行交錯操作。
在選擇了保證等級之後,我們需要為其找到一種演算法。到目前為止,我們已經使用較弱的一種實作來解決這個問題。但它需要與 GC 進行一些整合。這種整合目前是一個瓶頸,我們仍在迭代。目前,您需要知道,除非手動同步,否則共享陣列是不安全的。
在 Array 中發現的挑戰會出現在每個指標的操作中。指標是不安全的,在處理 Array 的程式碼時,我們絕對希望在語言中有安全/不安全的部分來指導審查過程。還有其他像 Deque 這樣的結構也有相同的問題。
下一步
雖然在我們可以聲稱多執行緒模式是該語言的一等公民之前,還有一些待完成的工作,但在運行時進行此更新絕對是一大進步。我們希望收集回饋並繼續迭代,以便在接下來的幾個版本中,我們可以從 preview_mt 中移除 preview。
我們能夠做到這一切,要感謝 84codes 和其他所有贊助商的持續支持。對我們來說,透過捐款來維持支持非常重要,這樣我們才能保持這種開發速度。OpenCollective 和 Bountysource 是兩個可用的管道。如果您想成為直接贊助商或找到其他支持 Crystal 的方式,請聯繫 crystal@manas.tech。我們在此先感謝您!